
¡5 DÍAS LÍMITE!
Del 10 al 14 de Abril
Cursos SAP Business One al 50% de descuento
Días
Horas
Mins
")
La Inteligencia Empresarial o Business Intelligence (BI) hace referencia al conjunto de estrategias y herramientas enfocadas a la administración y creación de conocimiento mediante el análisis de datos existentes en una organización o empresa. Es decir, es básicamente el análisis de la información o los datos obtenidos.
Dentro de la analítica, podemos encontrarnos diferentes sistemas o softwares que nos ayudan a recopilar la información y los datos, saber intepretarla correctamente y, por consiguiente, tomar mejores decisiones en la empresa. Uno de los softwares más conocidos es Apache Superset.
![]()
Superset o Apache Superset es una aplicación nativa de la nube de software de código abierto para la exploración y visualización de datos capaz de manejar datos a escala de petabytes.
Una moderna plataforma de exploración y visualización de datos rápida, liviana, intuitiva y repleta de opciones que facilitan a los usuarios de todos los conjuntos de habilidades la exploración y visualización de sus datos, desde gráficos de líneas simples hasta gráficos geoespaciales muy detallados.
Este sistema permite, entre otras funcionalidades, integrar y explotar los datos rápida y fácilmente, puede conectarse a cualquier fuente de datos basada en SQL a través de SQLAlchemy, incluidas las bases de datos y motores nativos de la nube modernos a escala de petabytes; cuenta con una amplia gama de hermosas visualizaciones y es liviano y altamente escalable.
Gracias a Superset, las empresas pueden obtener ventajas o beneficios como realizar exploración gráfica sin escribir código, hacer despliegues sencillos (instalación y configuración rápidas y guiadas), disponer de un entorno de laboratorio de SQL para consultas interactivas on demand, crear recursos de visualización como Pivot Tables para facilitar la exploración Drill Down Multiples recursos gráficos: pie charts, mapas,…, etc.
Para mostrar cómo funciona esta herramienta, pondremos como ejemplo un tutorial, en este caso la creación de un tablero o dashboard. Te enseñaremos cómo conectar Superset a una nueva base de datos y configurar una tabla en esa base de datos para su análisis, además de explorar los datos y agregar una visualización al tablero para que tengas una idea de la experiencia de usuario en esta herramienta.
Para ello hay que seguir los siguientes pasos:
Superset en sí mismo no tiene una capa de almacenamiento para almacenar sus datos, sino que se empareja con su base de datos o almacén de datos de habla SQL existente.
Lo primero que debemos hacer es agregar las credenciales de conexión a la base de datos para poder consultar y visualizar los datos de ella. Si estás utilizando Superset localmente a través de Docker compose, puedes omitir este paso porque una base de datos de Postgres, denominada ejemplos, ya está incluida y preconfigurada en Superset.
En el menú «Datos», tenemos que seleccionar la opción «Bases de datos»:
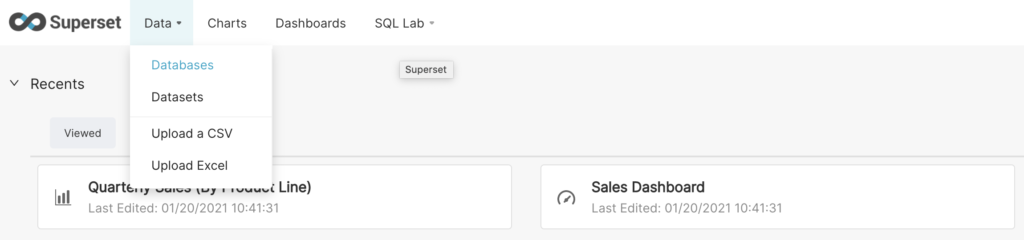
A continuación, hacemos clic en el botón verde + Base de datos en la esquina superior derecha:
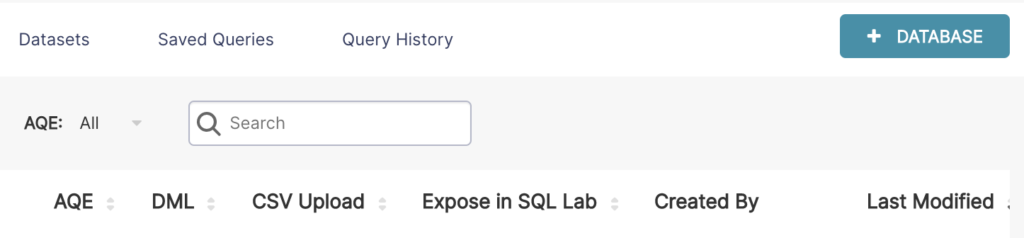
En esta ventana podemos configurar varias opciones avanzadas, pero para este caso prácico solo necesitamos especificar el nombre de la base de datos y el URI de SQLAlchemy:
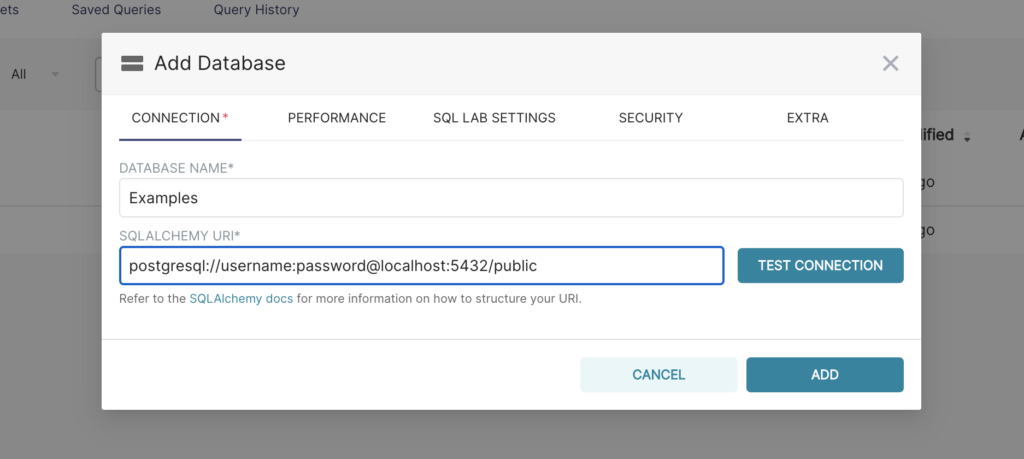
Como indica el texto debajo del URI, debemos consultar la documentación de SQLAlchemy sobre la creación de nuevos URI de conexión para nuestra base de datos de destino.
A continuación tienes que hacer clic en el botón «Probar conexión» para confirmar que todo funciona correctamente. Si la conexión se ve bien, guardas la configuración haciendo clic en el botón «Agregar» en la esquina inferior derecha de la ventana modal:
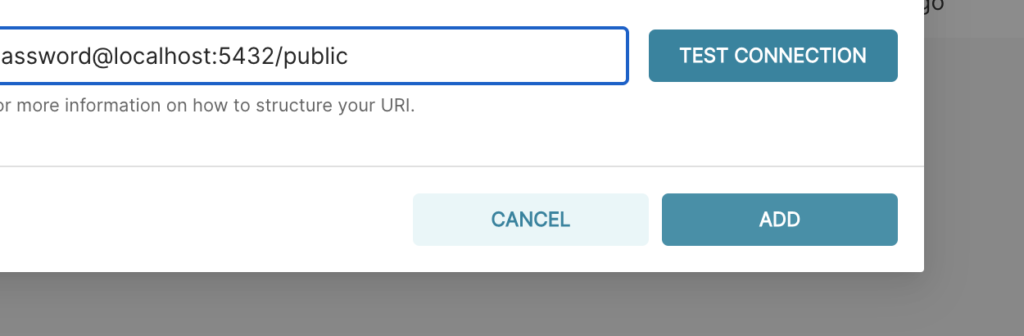
Ahora que hemos configurado una fuente de datos, podemos seleccionar tablas específicas (llamadas Conjuntos de datos en Superconjunto) que deseamos exponer en Superconjunto para realizar consultas.
Vamos a Datos ‣ Conjuntos de datos y seleccione el botón + Conjunto de datos en la esquina superior derecha.

Una ventana modal debería aparecer frente a nosotros. Seleccionamos la Base de datos. Esquema y Tabla usando los menús desplegables que aparecen. En el siguiente ejemplo, registramos la tabla clean_sales_data de la base de datos de ejemplos.
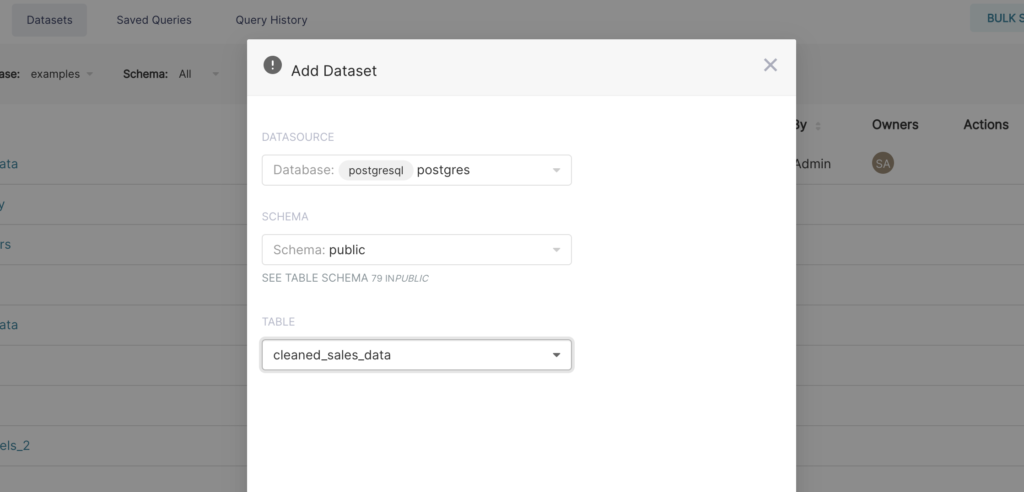
Para finalizar, hacemos clic en el botón Agregar en la esquina inferior derecha. Ahora deberíamos ver nuestro conjunto de datos en la lista de conjuntos de datos.
Ahora que hemos registrado nuestro conjunto de datos, podemos configurar las propiedades de la columna para saber cómo debe tratarse la columna en el flujo de trabajo Explorar:
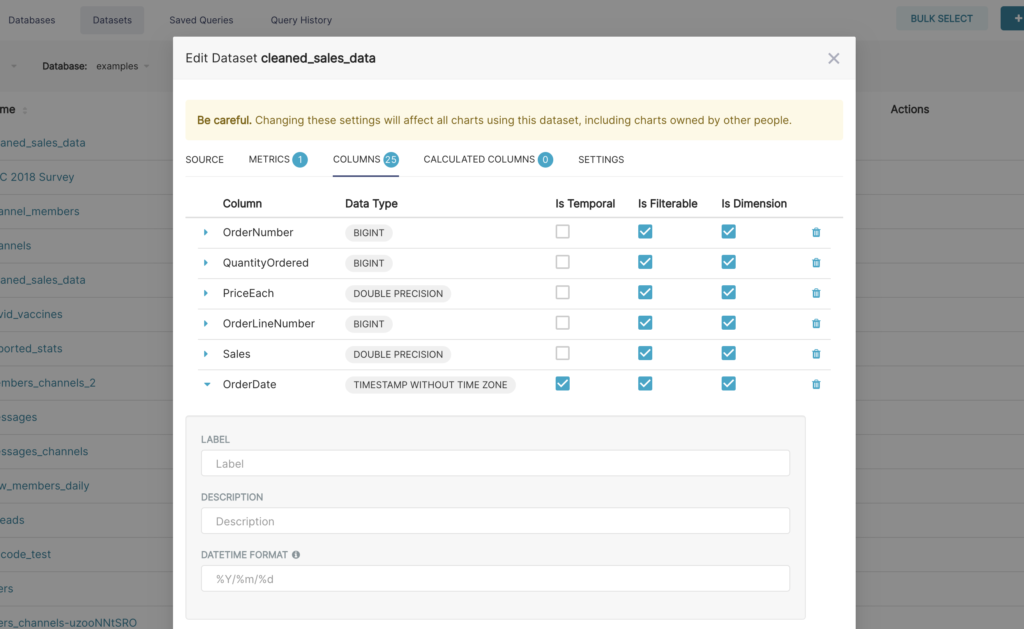
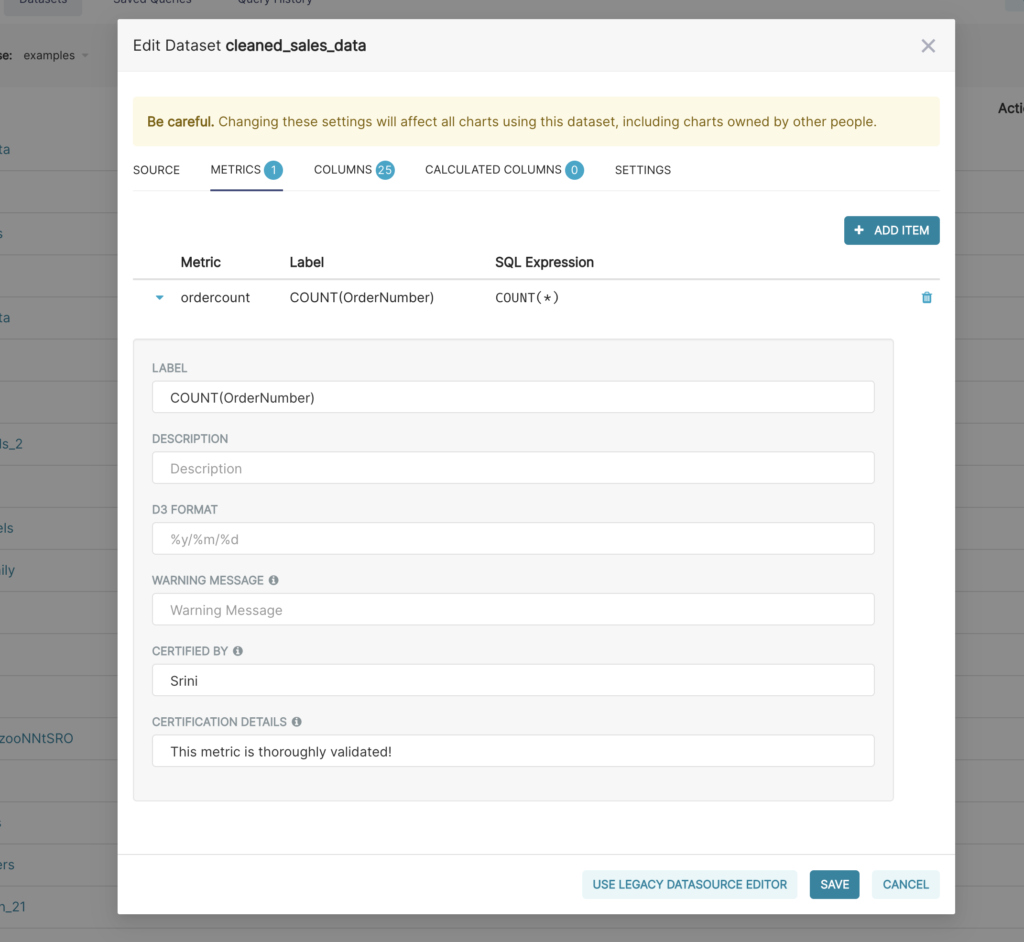
Superset tiene una capa semántica delgada que agrega muchas mejoras en la calidad de vida de los analistas. La capa semántica Superset puede almacenar 2 tipos de datos computados:
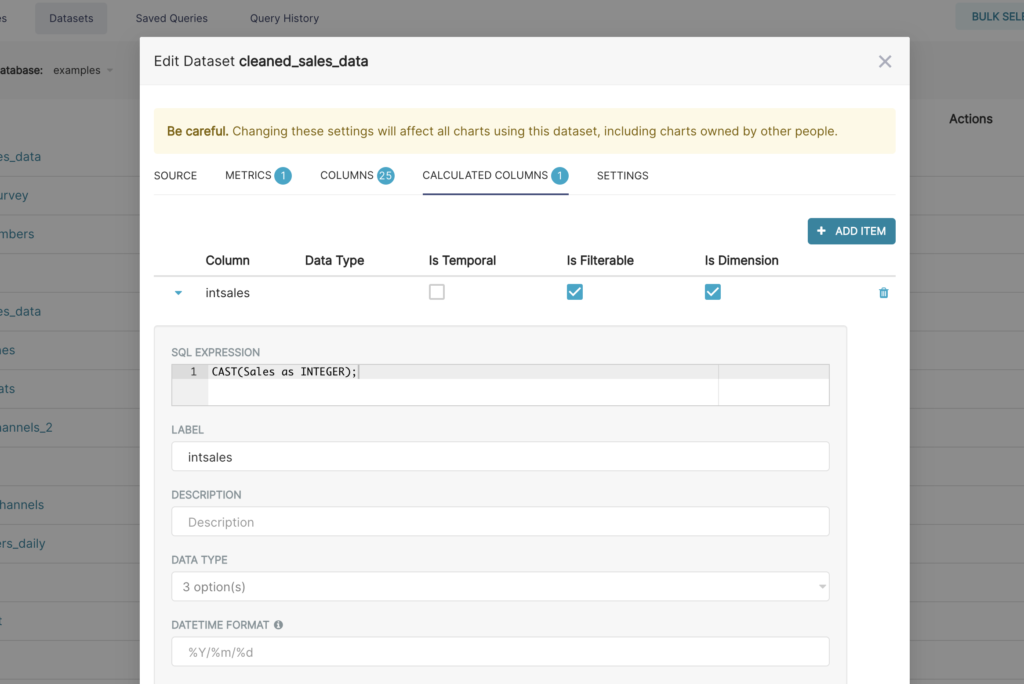
En el próximo artículo veremos cómo crear gráficos en la vista, la creación de una división y de un tablero, cómo administrar el acceso a los paneles y el panel de personalización.



Con nuestra newsletter recibirás guías, consejos de expertos y estrategias que impulsarán tu carrera y tus proyectos.
Del 10 al 14 de Abril
Cursos SAP Business One al 50% de descuento